
丝析发解丨zStorage 的尾延迟优化
发布时间:2024-11-01 02:30分类: 无 浏览:305评论:0
想象一下,您正在某宝上抢购限时秒杀商品。正当您兴奋地点击“立即购买”,准备享受这场购物盛宴时,却发现页面反应迟钝,等待时间异常漫长。最终,当页面加载完毕时,您错失了抢购机会。这种沮丧的体验,很可能是由于背后数据库的“尾延迟”问题所造成的。
对于存储系统来说,降低尾延迟是非常重要的。本文探讨:系统设计和优化应该考虑如何减少尾延迟,以保持和提升用户满意度。
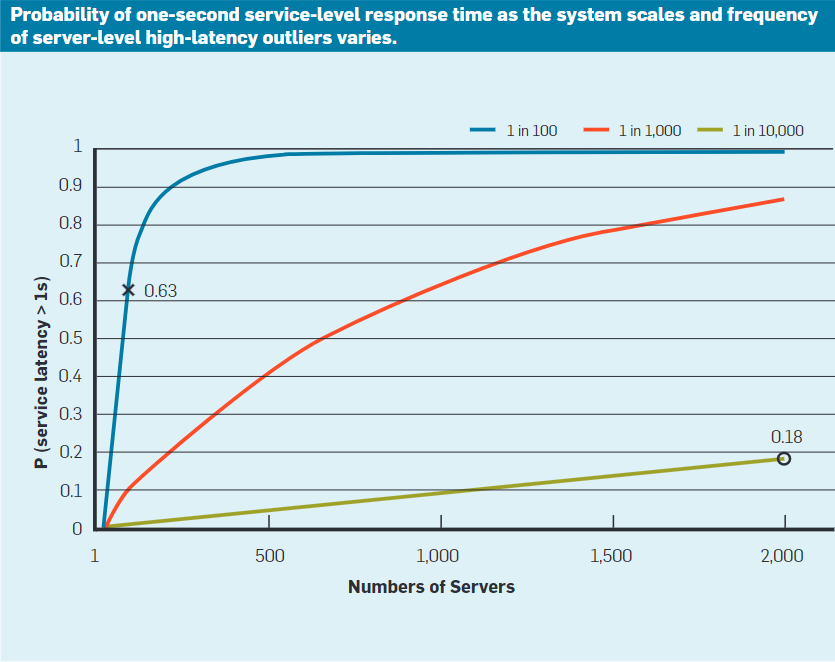
虽然 zStorage 处理一个IO请求只需要3-4个进程配合完成,但是NVMe SSD和网络本身存在尾延迟问题,尽量缓解这个问题,对 zStorage 依然很重要。

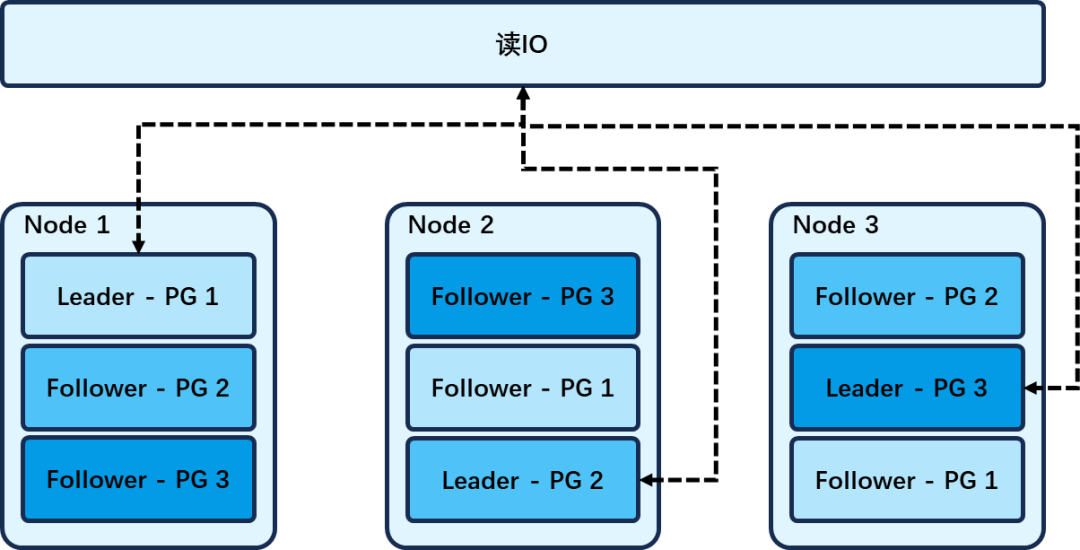

通过特定卷设置为高优先级卷,例如数据库将日志卷设置为高优先级卷。 支持智能识别数据库日志写请求,通过分析写请求,智能判断是否为高优先级写请求。
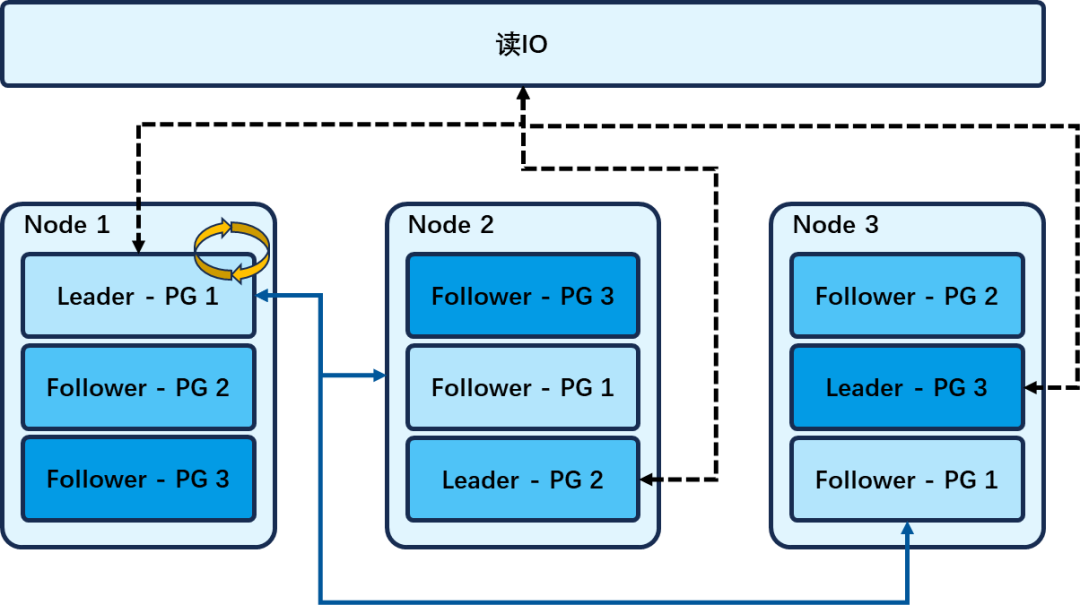
收集 Leader 之前处理过的一定数量的读请求时延数据,计算 P95 时延,当读请求的时延超过 P95 时延时,Leader将读请求转发到 Follower。这样可以避免过于频繁地转发读请求,同时也能保证系统的性能。 这里选择 P95 时延而不是 P99 时延,是因为根据《The Tail at Scale》[CACM2013]中统计数据显示对于单个随机请求,其99分位数的延迟是10毫秒。然而,当考虑所有请求时,99分位数的延迟升至140毫秒,而95%的请求在99分位数的延迟为70毫秒。这表明,最慢的5%的请求贡献了总99分位数延迟的一半。因此针对这些慢请求进行优化,可以对整体时延有巨大影响。 
收集与计算 P95 时延的过程需要一定的时间,因此需要合理地选择收集的数据量和计算的时间间隔,另外也需要选择合适的工业级算法,避免产生过多的计算开销和内存开销。这里给出一些常见的业界较为成熟的算法:
Rocksdb使用的histogram算法(https://github.com/facebook/rocksdb/blob/main/monitoring/histogram.cc) folly/facebook使用的t-digest算法(https://github.com/facebook/folly/blob/main/folly/stats/TDigest.cpp)
zStorage 在某些场景/工作模式下,例如流控模式,可以通过限制读请求的转发数量,或者开启/关闭请求转发,来保证当前系统的稳定性。
关于zStorage
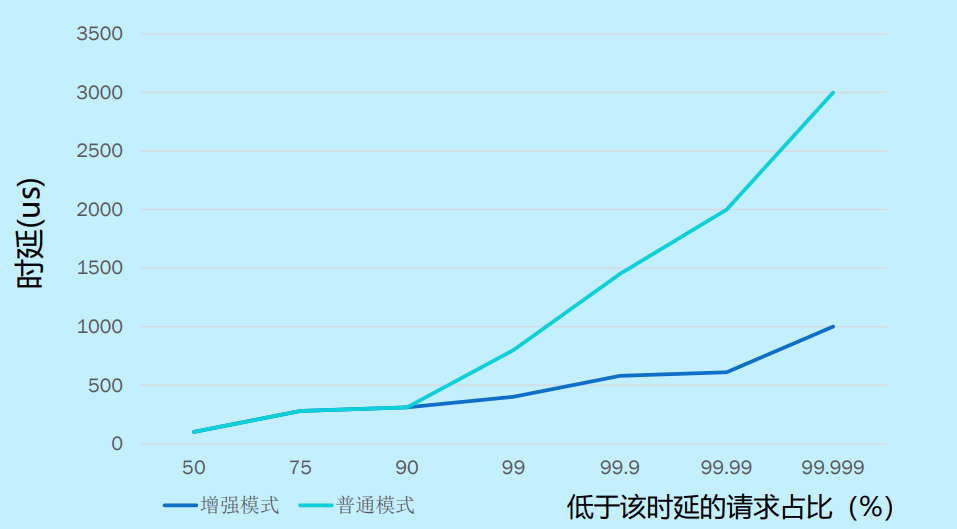
zStorage 是云和恩墨针对数据库应用开发的高性能全闪分布式块存储。三节点 zStorage 集群可以达到200万IOPS随机读写性能,同时平均时延<300μs、P99时延小于800μs。
zStorage 支持多存储池、精简配置、快照/一致性组快照、链接克隆/完整克隆、NVMeoF/NVMeoTCP、iSCSI、CLI和API管理、快照差异位图(DCL)、慢盘检测、亚健康管理、16KB原子写、2副本、强一致3副本、Raft 3副本、IB和RoCE、TCP/IP、后台巡检、基于Merkle树的一致性校验、全流程TRIM、QoS、SCSI PR、SCSI CAW。
zStorage 是一个存储平台,可作为数据库产品和存储产品的底座,欢迎发邮件至 marketing@enmotech.com 咨询。
关于作者

数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,是业界领先的“智能的数据技术提供商”。公司以“数据驱动,成就未来”为使命,致力于将创新的数据技术产品和解决方案带给全球的企业和组织,帮助客户构建安全、高效、敏捷且经济的数据环境,持续增强客户在数据洞察和决策上的竞争优势,实现数据驱动的业务创新和升级发展。
自成立以来,云和恩墨专注于数据技术领域,根据不断变化的市场需求,创新研发了系列软件产品,涵盖数据库、数据库存储、数据库云管和数据智能分析等领域。这些产品已经在集团型、大中型、高成长型客户以及行业云场景中得到广泛应用,证明了我们的技术和商业竞争力,展现了公司在数据技术端到端解决方案方面的优势。
相关文章
- 恒为科技助力“万卡智算集群服务推进方阵”加速构建自主智算体系
- 8月更新|睿人事工作台全新发布,轻松自定义你的“首页”!
- 口碑+| 冷链人速来围观!冷库智能升级方案已就位,锦江冷链同款get指南→
- 壹企秀|一起来点赞,见证荣誉时刻!
- 最新!TikTok恢复在美服务,特朗普曾发声:“挽救TikTok”
- MWC 2025丨中科创达携5G+AI双擎驱动 赋能端侧智能创新
- DeepSeek × Moka:双向赋能,定义智能招聘新标杆
- 福田汽车营销战略及产品发布会 共同见证新生态新产品
- 【行业践行 - 金融】动态安全在信创金融场景的典型应用
- 中科创达旗下Thundercomm重磅发布TurboX C6690:超紧凑型SOM为工业手持设备注入AI动力