
天工一刻 | 一文看懂3D大模型
发布时间:2024-09-28 03:46分类: 无 浏览:237评论:0

随着大模型技术迎来颠覆性突破,新兴AI应用大量涌现,不断重塑着人类、机器与智能的关系。
为此,昆仑万维集团重磅推出《天工一刻》系列产业观察栏目。在本栏目中,我们将对大模型产业热点、技术创新、应用案例进行深度解读,同时邀请学术专家、行业领袖分享优秀的大模型行业趋势、技术进展,以飨读者。
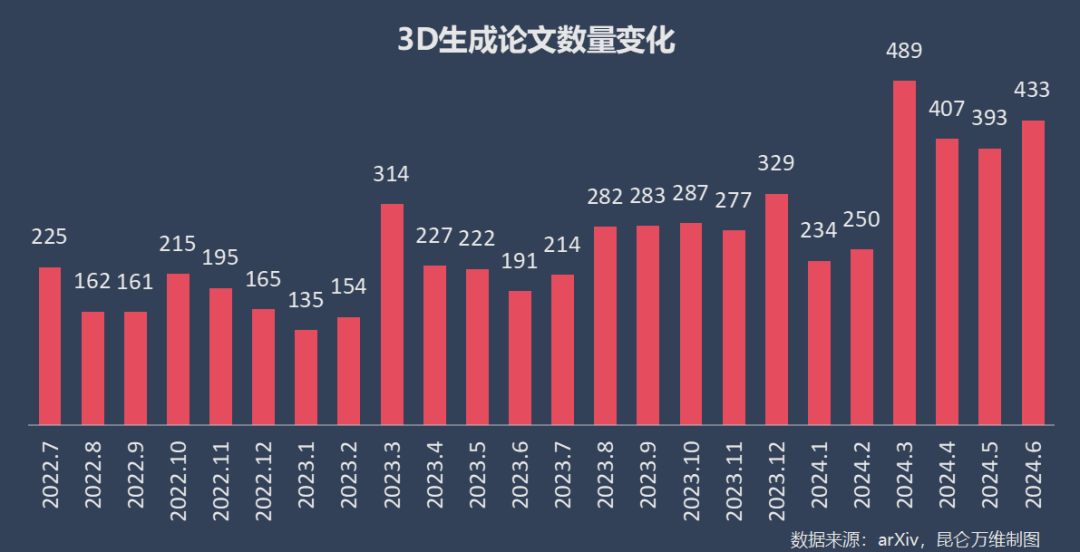
今年3月以来,arXiv上的3D生成(3D Generation)论文数量更是从200+篇/月飙升至400+篇/月,几乎飙升100%——这背后是3D模型多项核心技术取得突破,大量新兴研究涌现。
01.
传统3D模型设计:流程长、环节复杂、价格贵


以传统3D模型的生成为例,其制作环节可分为:概念设计/原画、3D建模、UV拆分、烘焙贴图、绘制材质、动画制作、渲染等诸多环节。

02.
流派众多,百花齐放
1、几何模型的形状准确度;
2、纹理贴图质量效果与“几何-纹理”一致性;
3、3D模型生成速度;
按照生成方式分类,主流3D生成的派别包括文生3D(text-to-3D)、图生3D(image-to-3D);
按照生成路径划分,根据论文《A Comprehensive Survey on 3D Content Generation》的分类,可以将3D大模型生成分为:2D升3D(2D prior-based 3D generative)、纯原生3D(3D native generative)、混合3D(hybrid 3D generative)三大派别;
根据3D建模方案划分,可以分为:点云(Point Cloud)、网格(Mesh)、深度(Depth)、神经场(Neural Fields)、混合(Hybrid)等多种方案;
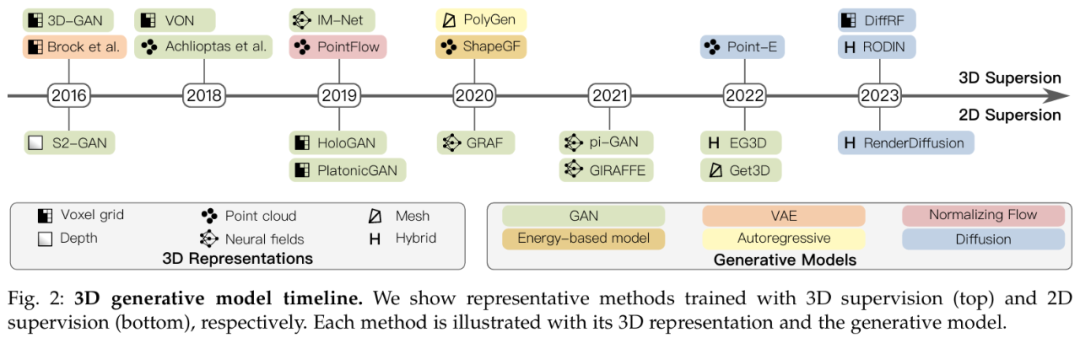
(3D生成模型技术发展路线,数据截止至2023年8月;来自论文《3D Generative Models: A Survey》)
根据3D生成模型划分,则包括GAN、VAE、Autoregressive、Diffusion等模型。
03.
3D大模型的三大主流路径
因此,早期3D生成模型的研究思路以“2D升3D”为主——先生成多视角的2D图像,然后根据该图像生成3D模型。
2D升3D
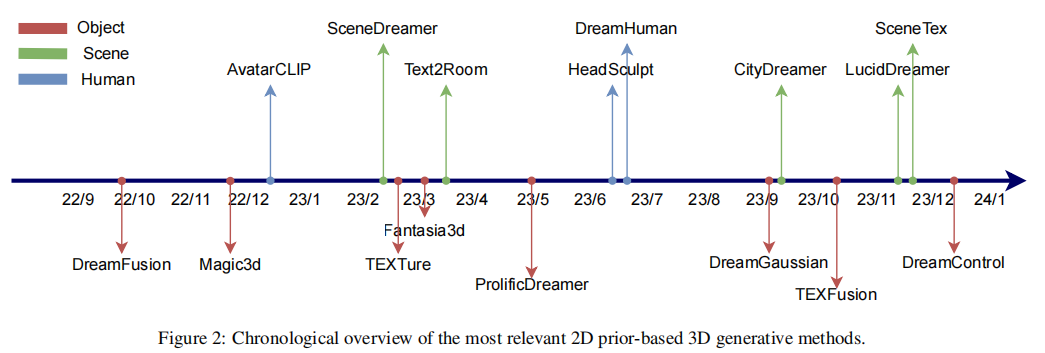
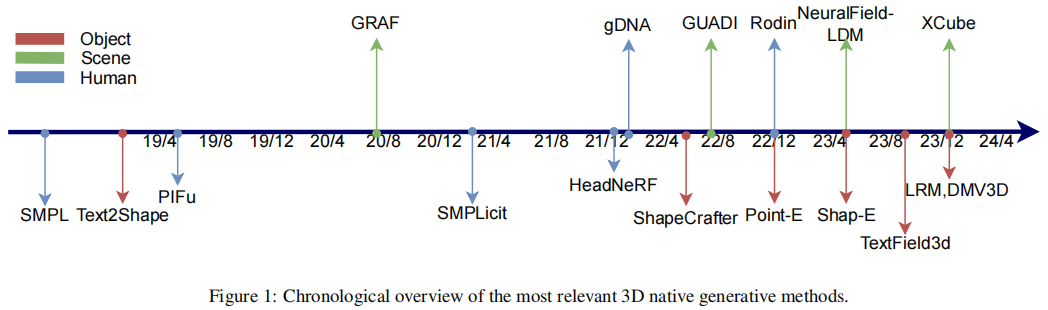
“纯原生”3D




“混合”3D
混合3D是当下3D大模型最前沿的技术方向,也是昆仑万维3D大模型团队专攻的技术方向。
由于纯原生3D路径训练数据不足,而2D升3D路径只能提取有限的3D几何知识。
因此,在最新的混合3D路径中,大模型研发人员将3D信息注入预训练的2D模型,例如,通过多视角图像微调Stable Diffusion模型,使其能够生成稳定、一致的3D模型。
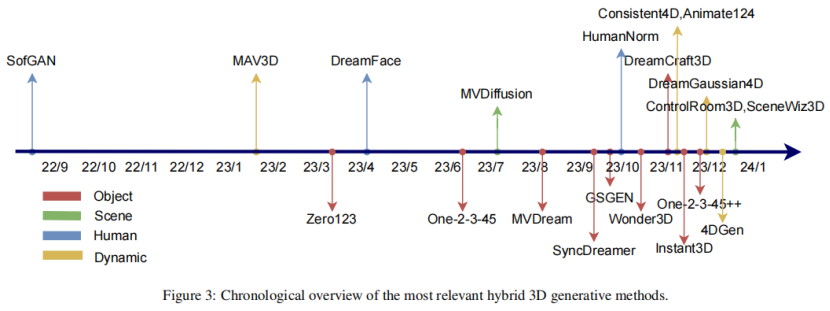
(“混合”3D大模型路径代表研究,来自论文《A Comprehensive Survey on 3D Content Generation》)
除了昆仑万维外,这前沿一思路的代表项目包括哥伦比亚大学的Zero123、加州大学与Adobe等的One-2-3-45、香港大学与腾讯游戏等的SyncDreamer、香港大学与清华大学等的Wonder3D、Adobe的Instant3D等等。
这一技术路径既利用了目前丰富的2D图像资源,规避了3D数据不足问题,又一定程度上突破了2D升3D带来的几何等多项问题。
当前,昆仑万维3D大模型团队坚持自研混合3D技术路线,在3D大模型两大核心领域(3D几何生成与3D纹理生成)均达到产业最领先水平。相较于同类产品,昆仑万维3D大模型有着极强的模型优势与数据壁垒,在3D大模型领域拥有三大产品技术亮点:
1.模型生成速度更快;
2.模型布线更加规则,方便接入游戏引擎;
3.模型纹理更加可控。

(昆仑万维2024年3月发布论文《InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting》)
(InTeX文生纹理效果Demo)
该模型通过将深度信息(Depth)与 inpainting纹理贴图相结合,解决了目前常见的预训练深度Diffusion + inpainting模型方案存在几何-纹理不一致、不可控问题,提高了模型生成速度,并能够允许用户实现特定区域的重新绘制和精确的纹理编辑。